
《深入理解并行编程》笔记


本文是《Is Parallel Programming Hard, And, If So, What Can You Do About It?》的中文翻译版《深入理解并行编程》的读书笔记(就是一些摘录整理,不想按照严格的文章进行书写,所以大佬们各取所需),虽然读书笔记一般是上传豆瓣,但是看到知乎上RCU内容很少,且自己有时从知乎上获得一些知识启发,算是回馈一下社区。由于时间不多,书没读完,内容也没贯通,后续会继续补更。
原著书作者Paul E.Mckenney,是Linux RCU Maintainer,本书很详细介绍了linux内核多核并行编程的干货,需要多精读。
硬件系统
霍金的半导体难题:1.有限的光速;2.物质的原子本质。这意味着在摩尔定律受阻,单核CPU性能难以提升,多核CPU大行其道的时代,多核CPU间通信代价高昂,需要注意性能影响。为了提升性能,硬件做了如下设计:
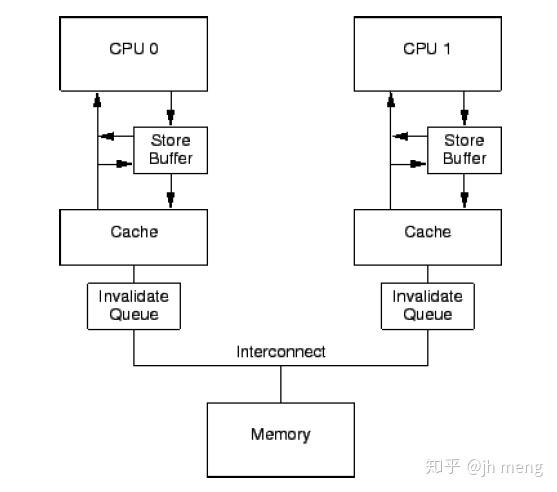

- 由于CPU速度远大于内存系统速度,CPU硬件中加入了缓存cache,cache与内存间数据传递是范围从16到256字节不等的缓存行cache-line。缓存缺失原因可能是startup cache miss(开始数据没有),capacity miss(容量满淘汰)以及communication miss(多个CPU间一致性同步使无效)。缓存缺失可能会导致CPU stall
- 由于一个变量可能缓存在多个CPU的cache中,多个CPU的cache需要一致性协议MESI进行同步。MESI协议即缓存行中modified(单CPU拥有最新修改的缓存数据),exclusive(单CPU独占缓存与内存最新数据),shared(数据由多个CPU共享),invalid(空数据)四种状态间进行转移
- CPU除了cache,还有存储缓冲store buffer。这是为了提高对于特定缓存行的第一次写操作的miss,比如foo = 1操作可能因为foo一致性同步而造成CPU停顿(等待使无效应答),这样CPU只需将新写数据保存到store buffer就可继续运行
- 由于store buffer通常很小,密集读写操作会造成大量使无效消息,因此增加使无效队列invalidate queue。带使无效队列的CPU可以迅速应答一个使无效消息,而不必等待相应的行真正变成无效状态。这意味着在没有真正将cache无效前,就告诉其他CPU已经使无效了。这多少有一点欺骗的意思
内存屏障
由于以上硬件设计,CPU被设计成在从内存中获取数据的同时可以执行其他指令,这明显会导致指令和内存引用的乱序执行(执行顺序与代码顺序不同),因而编译器和同步原语有责任通过对内存屏障的使用来保护在并行编程中用户的直觉。
简单规则:
- 一个特定CPU将像“编程顺序”那样看到它对内存的访问操作
- 单变量存储序列一致
- 内存屏障将成对操作。不能保证一个CPU将看到第二个CPU访问操作的正确顺序,即使第二个CPU使用一个内存屏障,除非第一个CPU也使用一个配对的内存屏障
- 互斥锁原语提供保护。申请,释放锁必须以全局顺序被看到
- 不能保证在内存屏障之前的内存访问将在内存屏障指令完成时完成
- 仅仅在两个CPU之间或者CPU与设备之间需要交互时,才需要内存屏障
内存屏障分类:
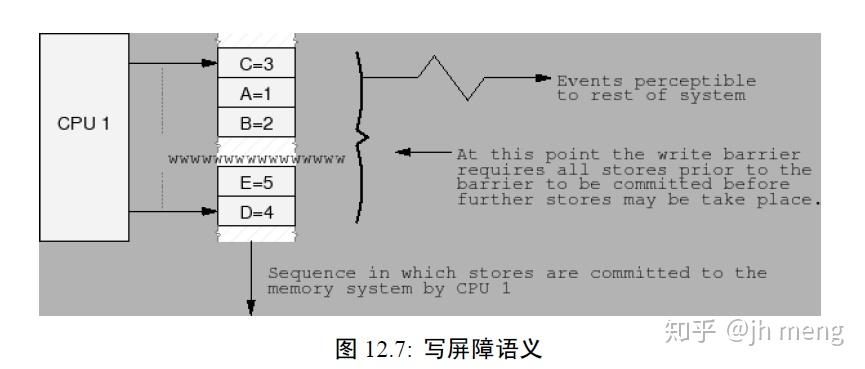
- 写内存屏障:CPU可以被视为按时间顺序提交一系列存储操作,所有在写屏障之前的存储操作将发生在所有屏障之后的存储操作之前。写屏障仅仅对写操作进行排序,对加载没有任何效果。注意写屏障通常应当与读或者数据依赖屏障配对使用
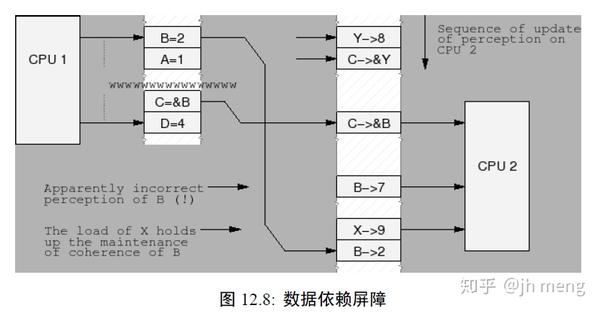
- 数据依赖屏障:弱的读屏障。当两个装载操作中,第二个依赖于第一个的结果时 (如第一个装载得到第二个装载的地址),需要一个数据依赖屏障,以确保第二个装载的目标将在第一个地址装载之后被更新。数据依赖屏障仅仅对相互依赖的加载进行排序。它对任何存储没有效果,对相互独立的加载或者重叠加载也没有效果。注意第一个装载实际上需要一个数据依赖而不是控制依赖。如果第二个装载的地址依赖于第一个装载,但是依赖的是一个条件而不是实际装载地址本身(if-else选择), 那么它就是一个控制依赖,这需要一个完整的读屏障
- 读内存屏障:所有在屏障之前的加载操作将在屏障之后的加载操作之前发生。读屏障仅仅对加载进行排序,它对存储没有任何效果。读内存屏障隐含数据依赖屏障,因此可以替代它。
- 通用内存屏障:通用内存屏障保证屏障之前的加载、存储操作都将在屏障之后的加载、存储操作之前被系统中的其他组件看到。通用内存屏障同时对加载和存储操作进行排序。通用内存屏障隐含读和写内存屏障,因此也可以替换它们中的任何一个
- 锁原语隐含内存屏障:LOCK操作确保所有LOCK操作后面的内存操作看起来发生在锁操作之后,LOCK锁操作之前的内存操作可能发生在它完成之后。UNLOCK 操作确保在UNLOCK操作之前的所有内存操作看起来发生在锁操作之前,UNLOCK操作之后的内存操作看起来可能发生在它完成之前。LOCK后面跟随UNLOCK不能设定为全内存屏障,因为LOCK之前的操作可能发生在LOCK之后,并且UNLOCK之后的访问可能发生在UNLOCK之前,因此这两个访问可能相互交叉
SMP屏障对:
一个写屏障应当总是与数据依赖屏障或者读屏障配对,虽然通用屏障也是可以的。类似的一个读屏障或者数据依赖屏障总是应当与至少一个写屏障配对使用,虽然通用屏障也是可以的。



写屏障图解:

数据依赖屏障图解:





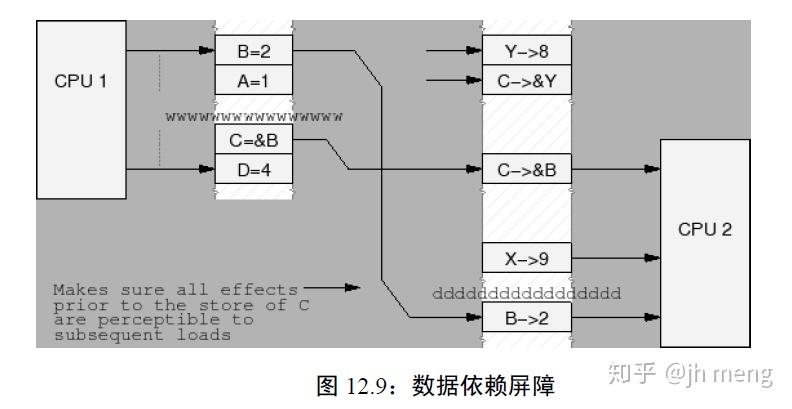

读内存屏障图解:
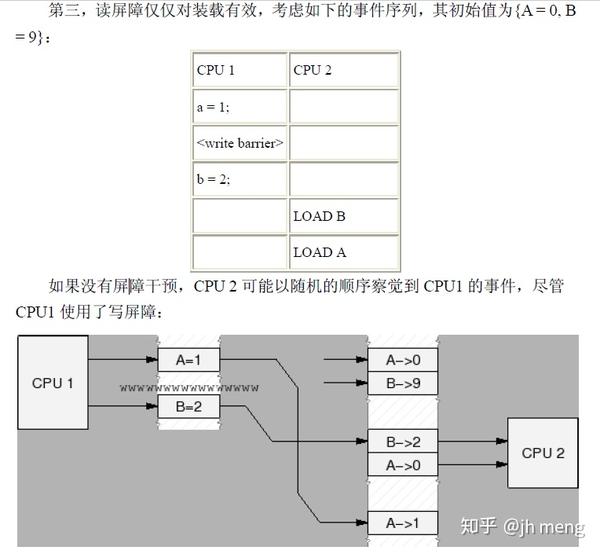

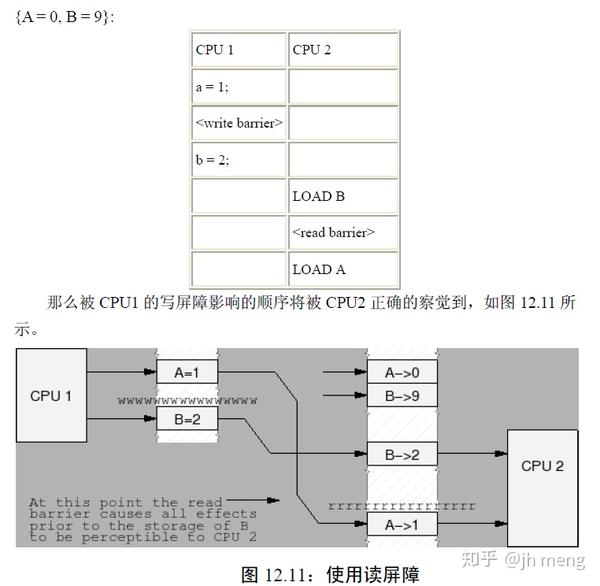



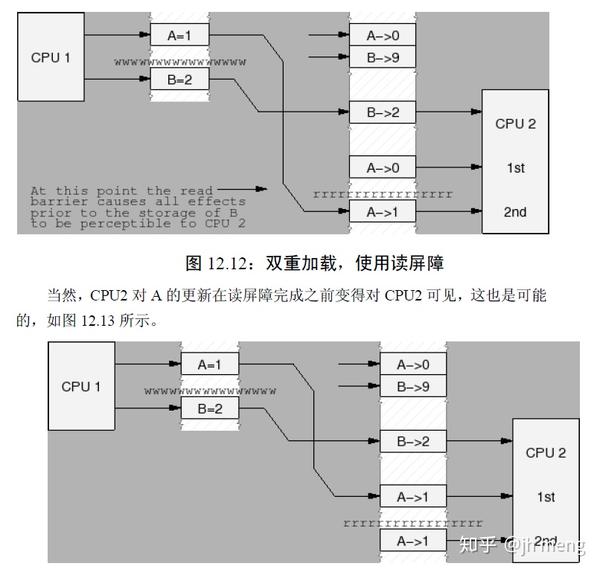

多CPU使用同一个锁的顺序:


c++11内存模型:


RCU
并行编程要注意性能与安全性。可以使用锁之类的同步原语,简单可靠,但是多核CPU同步造成扩展时性能降低。或者使用内存屏障与原子指令,但是编程复杂,很容易就犯难以察觉的错误。过于轻率地使用大锁或者原子变量,由于CPU缓存一致性同步造成可扩展性不够。这时有种策略就是延迟处理,通用的并行编程延后技术包括排队、引用计数和RCU。
引用计数跟踪一个对象被引用的次数,防止对象过早的被释放。Linux内核中kref:
1 struct kref {
2 atomic_t refcount;
3 };
4
5 void kref_init(struct kref *kref)
6 {
7 atomic_set(&kref->refcount,1);
8 }
9
10 void kref_get(struct kref *kref)
11 {
12 WARN_ON(!atomic_read(&kref->refcount));
13 atomic_inc(&kref->refcount);
14 }
15
16 int kref_put(struct kref *kref,
17 void (*release)(struct kref *kref))
18 {
19 WARN_ON(release == NULL);
20 WARN_ON(release == (void (*)(struct kref *))kfree);
21
22 if ((atomic_read(&kref->refcount) == 1) ||
23 (atomic_dec_and_test(&kref->refcount))) {
24 release(kref);
25 return 1;
26 }
27 return 0;
28 }Read-copy-update(RCU)是一种同步机制,于2002年10月引入Linux内核。RCU允许读操作可以与更新操作并发执行,这一点提升了程序的可扩展性。RCU定义并使用了高效并且易于扩展的机制,用来发布和读取对象的新版本,还用于延后旧版本对象的垃圾收集工作。这些机制恰当地在读端和更新端工作,让读端非常快速。在某些场合下(比如非抢占式内核里),RCU读端的函数完全是零开销。

- RCU保护的是指针
- 发布-订阅机制:RCU通过一种发布-订阅机制达成了并发的数据插入。可以安全的读取数据,即使数据此时正被修改。linux中使用rcu_assign_pointer()原语来发布新数据,其将指针p用内存屏障封装起来,强制让编译器和CPU在为p的各字段赋值后再发布。使用rcu_dereference()原语依靠各种内存屏障指令和编译器指令来订阅指针的值
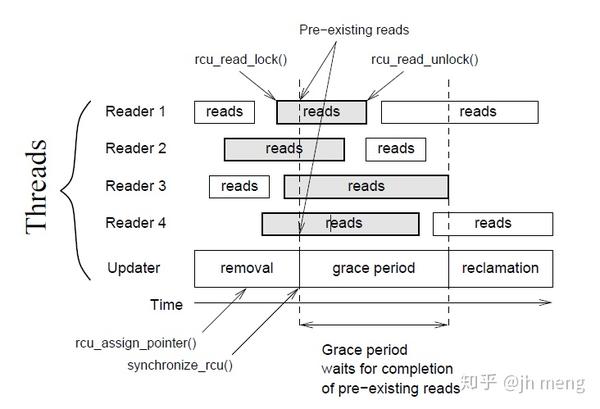
- 等待已有的RCU读者执行完毕:RCU就是一种等待事物结束的方式。RCU的最伟大之处在于它可以等待多种不同的事物,而无需显式地去跟踪它们中的每一个,也无需去担心对性能的影响,对扩展性的限制,复杂的死锁场景,还有内存泄漏带来的危害等等使用显式跟踪手段会出现的问题。被等待的事物称为“RCU读端临界区”。RCU读端临界区从rcu_read_lock()原语开始,到对应的rcu_read_unlock()原语结束。RCU读端临界区可以嵌套,也可以包含一大块代码,只要这其中的代码不会阻塞或者睡眠(先不考虑可睡眠RCU)。如果你遵守这些约定,就可以使用RCU去等待任何代码的完成。RCU是一种等待已有的RCU读端临界区执行完毕(比如使用synchronize_rcu()原语)的方法,这里的执行完毕也包括在临界区里执行的内存操作,请注意在某个宽限期开始后才启动的RCU读端临界区会扩展到该宽限期的结尾处。算法是:改变原数据,比如替换链表中的一个元素;等待所有已有的RCU读端临界区执行完毕,即优雅宽限期(grace peroid)结束;再清理,比如释放刚才被替换的元素
- 维护最近被更新对象的多个版本:允许在不影响或者延迟其他并发RCU读者的前提下改变数据。这意味着RCU保护的是内存不一致的数据结构,即存在多个版本,更新数据时,旧版本数据与新版本数据可能被不同读者读到
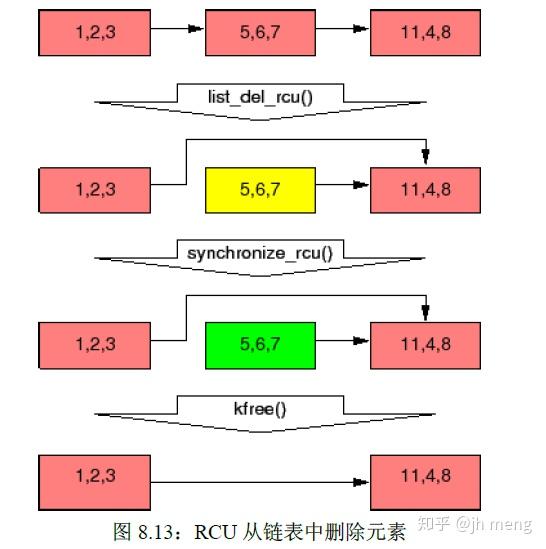

RCU使用:
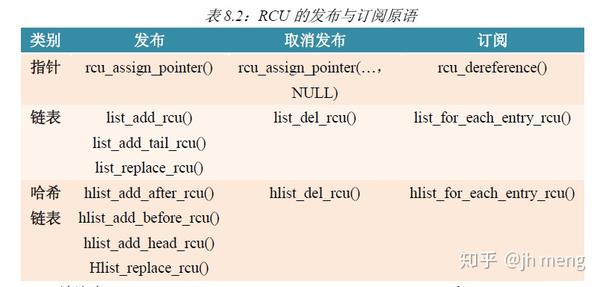







RCU优点:
- RCU是读写锁的替代者。也许在Linux内核中RCU最常见的用途就是在读占大多数时间的情况下替换读写锁了。RCU的优点在于性能,读端不会死锁,以及良好的实时延迟。当然RCU也有一点缺点,比如读者与更新者并发执行,低优先级RCU读者也可以阻塞正等待优雅周期(Grace Period)结束的高优先级线程,优雅周期的延迟可能达到好几毫秒。RCU这种免于死锁的能力来源于RCU的读端原语不阻塞、不自旋,甚至不会向后跳转,所以RCU读端原语的执行时间是确定的,这使得RCU读端原语不可能组成死锁循环,也保证实时延迟。RCU读端免于死锁的能力带来了一个有趣的后果,RCU读者可以无条件地升级为RCU更新者,在读写锁中尝试这种升级则会造成死锁。RCU免于死锁的特性带来的另一个有趣后果是RCU不会受很多优先级反转问题影响。比如低优先级的RCU读者无法阻止高优先级的RCU更新者获取更新端锁。类似地,低优先级的更新者也无法阻止高优先级的RCU读者进入RCU读端临界区。RCU读者与更新者并发执行,但读写锁和RCU提供了不同的保证。在读写锁中,任何在写者之后开始的读者都“保证”能看到新值,而在写者正在自旋时开始的读者有可能看见新值,也有可能看见旧值,这取决于读写锁实现中的读者/写者哪一个先获得锁。与之相反,在RCU中,在更新者完成后才开始的读者都“保证”能看见新值,在更新者开始后才完成的读者有可能看见新值,也有可能看见旧值,这取决于具体的时机。
- RCU是一种受限制的引用计数机制:rcu_read_lock()原语可以看作是获取对p的引用,因为相应的优雅周期无法在配对的rcu_read_unlock()之前结束。这种引用计数机制是受限制的,因为我们不允许在RCU读端临界区中阻塞,也不允许将一个任务的RCU读端临界区传递给另一个任务。和读写锁一样,RCU的性能优势主要来源于较短的临界区
- RCU是一种bulk引用计数机制:传统的引用计数通常与某种或者一组数据结构有联系,然而维护一组数据结构的全局引用计数,通常会导致包含引用计数的缓存行来回“乒乓”,这种缓存行“乒乓”会严重影响系统性能。相反,RCU的轻量级读端原语允许读端极其频繁地调用,却只带来微不足道的性能影响,这使得RCU可以作为一种几乎没有性能损失的“批量引用计数机制”
- RCU是穷人版的垃圾回收器:RCU类似自动决定回收时机的GC,但是RCU与GC有几点不同:程序员必须手动指示何时可以回收指定数据结构,且程序员必须手动标出可以合法持有引用的RCU读端临界区
- RCU是一种提供存在担保的方法:与锁类似,如果任何受RCU保护的数据元素在RCU读端临界区中被访问,那么数据元素在RCU读端临界区持续期间保证存在
- RCU是一种提供类型安全内存的方法:很多无锁算法并不需要数据元素在被RCU读端临界区引用时保持完全一致,只要数据元素的类型不变就可以了。换句话说只要数据结构类型不变,无锁算法可以允许某个数据元素在被其他对象引用时被释放并重新分配,但是决不允许类型上的改变,这种“保证”在学术文献中被称为“类型安全的内存”
- RCU是一种等待事物结束的方式

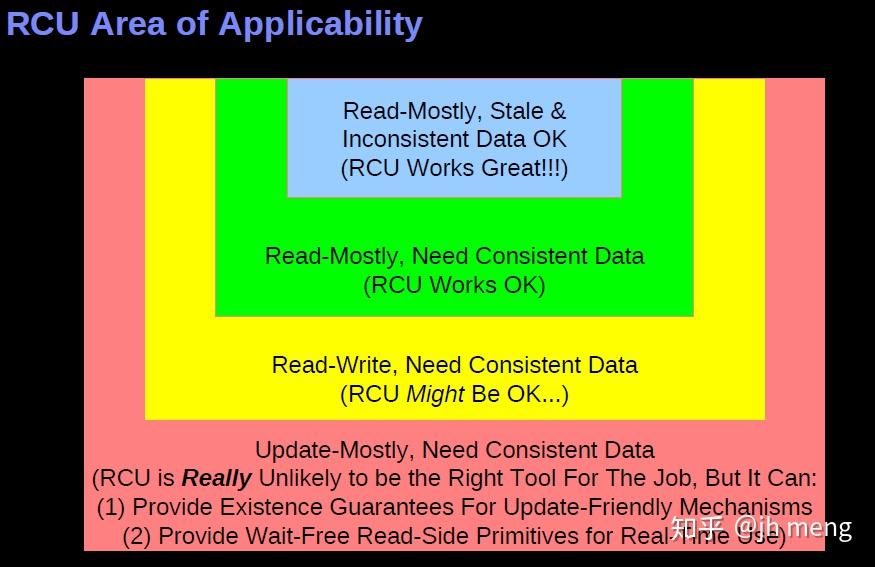
RCU实现:
仅讨论userspace rcu,具体论文参考User-Level Implementations of Read-Copy Update。书中详细讨论了设计演进的过程,渐渐完善RCU原语使其符合原来定义。
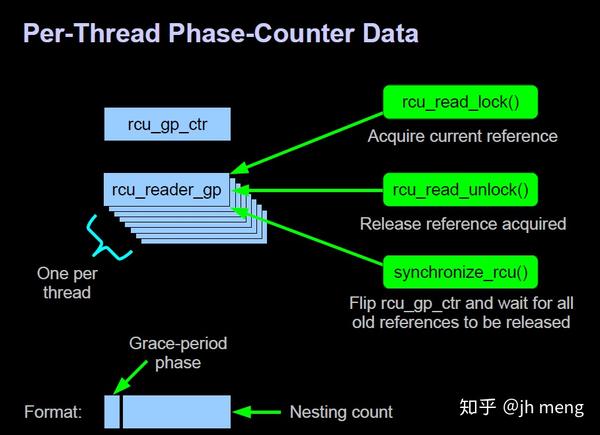
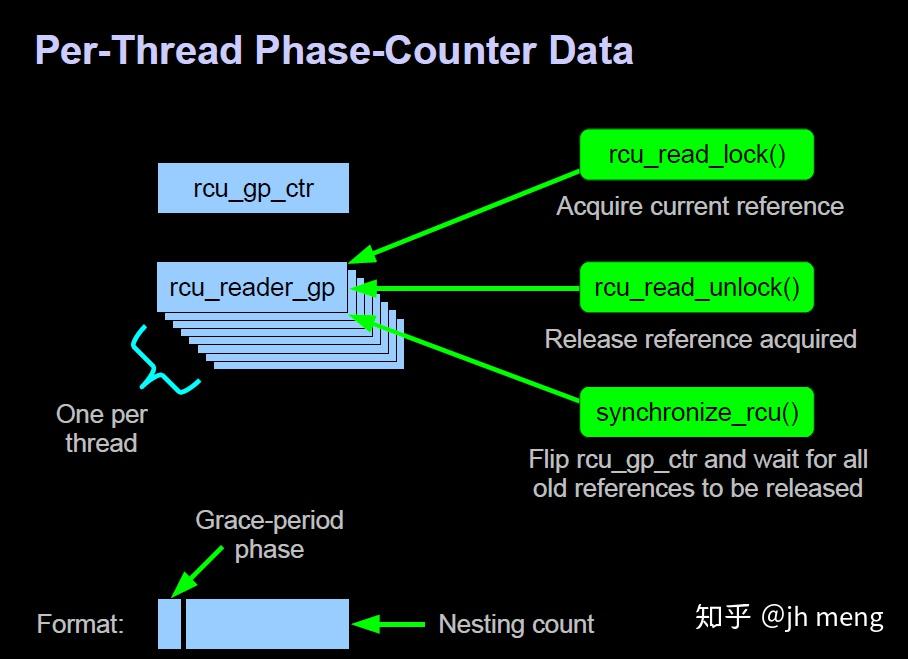








是一种基于单个全局free-running计数器的RCU实现,但是允许RCU读端临界区的嵌套。嵌套通过全局变量rcu_gp_ctr实现,RCU_GP_CTR_NEST_MASK宏则是rcu_gp_ctr中所有用于记录嵌套的位掩码。
rcu_read_lock()的实现中,第6行指向本线程rcu_reader_gp实例的指针放入局部变量rrgp中,将代价昂贵的访问每线程变量函数的数目降到最低。第8行检查低位字节是否为0,表明当前的rcu_read_lock()是最外层的。如果是,第9行将全局变量rcu_gp_ctr的值存入tmp,因为第7行之前存入的值可能已经过期了,如果不是,第10行增加嵌套深度。第11行将更新后的计数器值重新放入当前线程的rcu_reader_gp实例中,最后第12行执行一个内存屏障,防止RCU读端临界区泄漏到rcu_read_lock()之前的代码里。除非当前调用的rcu_read_lock()是嵌套在RCU读端临界区中,否则本节实现的rcu_read_lock()原语会获取全局变量rcu_gp_ctr的一个副本,而在嵌套环境中,rcu_read_lock()则去获取rcu_reader_gp在当前线程中的实例。在两种情况下,rcu_read_lock()都会增加获取到的值,表明嵌套深度又增加了一层,然后将结果储存到当前线程的rcu_reader_gp实例中。
rcu_read_unlock()的实现。第19行执行一个内存屏障,防止RCU读端临界区泄漏到rcu_read_unlock()之后的代码中去,然后第20行减少当前线程的rcu_reader_gp实例,这将减少rcu_reader_gp低几位包含的嵌套深度。
synchronize_rcu()的实现,只需要等待“在调用synchronize_rcu()之前就已存在的”RCU读端临界区。第24行执行一个内存屏障,防止之前操纵的受RCU保护的数据结构被乱序(由编译器或者是CPU)放到第24行之后执行。为了防止多个synchronize_rcu()实例并发执行,第25行获取rcu_gp_lock锁(第29释放锁)。然后第13行给全局变量rcu_gp_ctr异或,使得synchronize_rcu()之后就存在的RCU读端临界区的rcu_reader_gp位最高端为0。然后16行扫描所有线程检查RCU_GP_CTR_BOTTOM_BIT指示的位是否为0及是否是之前的rcu_gp_ctr,为0则表示已经不在临界区,为1表示是synchronize_rcu()之前就已存在的RCU读端临界区。flip_counter_and_wait执行两次恢复rcu_gp_ctr的最高位为1。最后第30行的内存屏障保证所有后续的销毁工作不会被乱序到循环之前进行.